I recently joined the team at Fly.io, and have slowly been moving my various sites and hobby projects over. In case you haven't heard of Fly.io, we help developers host apps (all sorts of apps, not only JavaScript-based ones) close to users – no devops skills required. I use Fly.io to host a few Python apps like this one and this one.
The Moon
There was a "blood moon" eclipse tonight. I've never tried photographing the moon before – mostly because I didn't own a telephoto lens until recently. The photo below was captured at 840mm (1260mm FF-equivalent). It's crazy to think this giant rock is just chilling up there.

EXIF
- X-H2S
- XF150-600mmF5.6-8 R LM OIS WR + 1.4x
- 840mm, 1s, f/11, ISO 1600
- 📷 View Original
{kind=link}
Shonan Sunset
One perk of living in Shonan is being able to see sunsets like this one.

EXIF
- X-H2S
- XF50-140mmF2.8 R LM OIS WR
- 119.2mm, 1/125s, f/2.8, ISO 640
- 📷 View Original
{kind=link}
Enoshima Sunset
Enoshima is always crowded on the weekends, but at least the sunsets are pretty. Joking aside, it was nice to stop by before the end of the summer. There were a bunch of restaurants and bars on the beach, and it was great to see people socializing and having fun again.

EXIF
- LEICA M10-R
- Summicron-M 1:2/35 ASPH.
- 35mm, 1/750s, f/2, ISO 100
- 📷 View Original
{kind=link}
How to Use Python to Get the Number of Commits to a GitHub Repository
Recently, I've been working on a page to track GitHub activity for ICON-related repositories. The page has a component that displays every commit made to the tracked repositories. This component is powered by a background service that scrapes GitHub's API for new commits every few minutes, and stores new commits in a MongoDB database.
As you can imagine, this task is fairly resource-intensive (especially for repos with a large number of commits) because GitHub only displays up to 100 commits on each API call. So, scraping commit data from a repo with 5,000 commits would require 50 API calls.
To make things a bit more efficient, I added some additional logic that queries the database for all commits to a repo, queries the GitHub API for the total number of commits, and compares the two numbers. If the two numbers are equal, the background service can just skip the resource-intensive API calls for the given repo.
Here's a simplified version of the function I wrote to get the number of commits to a GitHub repo:
import requests
from urllib.parse import parse_qs, urlparse
def get_commits_count(self, owner_name: str, repo_name: str) -> int:
"""
Returns the number of commits to a GitHub repository.
"""
url = f"https://api.github.com/repos/{owner_name}/{repo_name}/commits?per_page=1"
r = requests.get(url)
links = r.links
rel_last_link_url = urlparse(links["last"]["url"])
rel_last_link_url_args = parse_qs(rel_last_link_url.query)
rel_last_link_url_page_arg = rel_last_link_url_args["page"][0]
commits_count = int(rel_last_link_url_page_arg)
return commits_countSwitching Back to Cloudflare Pages
Back in December 2020, I tried out Cloudflare Pages for the first time during its public beta. After a few days of trying to get it to work with my blog, I gave up and reverted back to the always trusty Vercel.
Long story short, Cloudflare Pages was still very new at that point and there were some compatibility issues with a few of the larger images on my blog. Also, site builds were taking upwards of 10 minutes on Cloudflare, versus 1-2 minutes on Vercel.
Recently, I decided to take a look at Cloudflare Pages again because of Imgix' new pricing model. I used Imgix to generate different sized variants of images on my blog because I don't like the WordPress model of storing multiple sizes of the same image locally – it's a waste of space. Imgix used to offer a cheap plan with generous limits, and my monthly bill never surpassed $8. The new pricing model includes a free plan that supports 1,000 origin images and unlimited transformations. Unfortunately, I don't qualify for this plan because I have too many images on my blog.
The funny thing is I was actually grandfathered in on the old plan, but I wanted to take advantage of the two origin sources offered on the new free plan. After switching to the new plan, I was excited to reduce my monthly costs for hosting this blog. A few days later, I got a notification that I had exceeded 1,000 origin images and Imgix would no longer serve new images unless I upgraded to a paid plan – the cheapest of which is $75/month.
Here's a breakdown of Imgix' new pricing model:
- Free ($0/month) – 1,000 origin images, 2 sources
- Basic ($75/month) – 5,000 origin images, 5 sources
- Growth ($300/month) – 25,000 origin images, 10 sources
To me, this pricing model feels weird because $0/month to $75/month is too big of a jump. I'd love to see a $15-$20/month "Creator" tier that offers 5,000 origin images and one source because I get the feeling that photography-centric bloggers like me don't really care about the number of sources – we just need support for a lot of images.
At this point, I had two options:
- Reduce the number of images on my blog.
- Find a different provider for image resizing.
Option 1 obviously wasn't happening, so I started looking for a new provider. After exploring various options, I ended up going with the Image Resizing feature that's included with Cloudflare's $20/month Pro Plan. I didn't mind the $20/month fee because it's a whole lot cheaper than paying $75/month to Imgix for image resizing ONLY.
Here are a few of my favorite features on the Cloudflare Pro plan:
- Dynamic image resizing
- Image optimization with Cloudflare Polish
- Built-in web analytics (this allowed me to get rid of my $14/month Fathom Analytics subscription as well)
- Support for Automatic Signed Exchanges
- Super fast global CDN
While migrating my image resizing stack to Cloudflare, I decided to give Cloudflare Pages another shot as well. I'm happy to report that the Pages product has been polished (no pun intended) significantly since I last tried it. After linking my blog's GitHub repository to Cloudflare Pages, it was able to build and deploy the site in less than two minutes with zero issues. Best of all, I ran a few page speed tests and found that Cloudflare Pages is slightly faster than Vercel and Netlify.
I'm glad I was able to move my entire stack (DNS, hosting, and image resizing) to Cloudflare. If you use a static site generator like Hugo to power your blog, I highly recommend hosting on Cloudflare Pages and taking advantage of the powerful features on Cloudflare's Pro Plan as well.
Leica M10 Monochrom
I recently picked up a Leica M10 Monochrom. More to come.
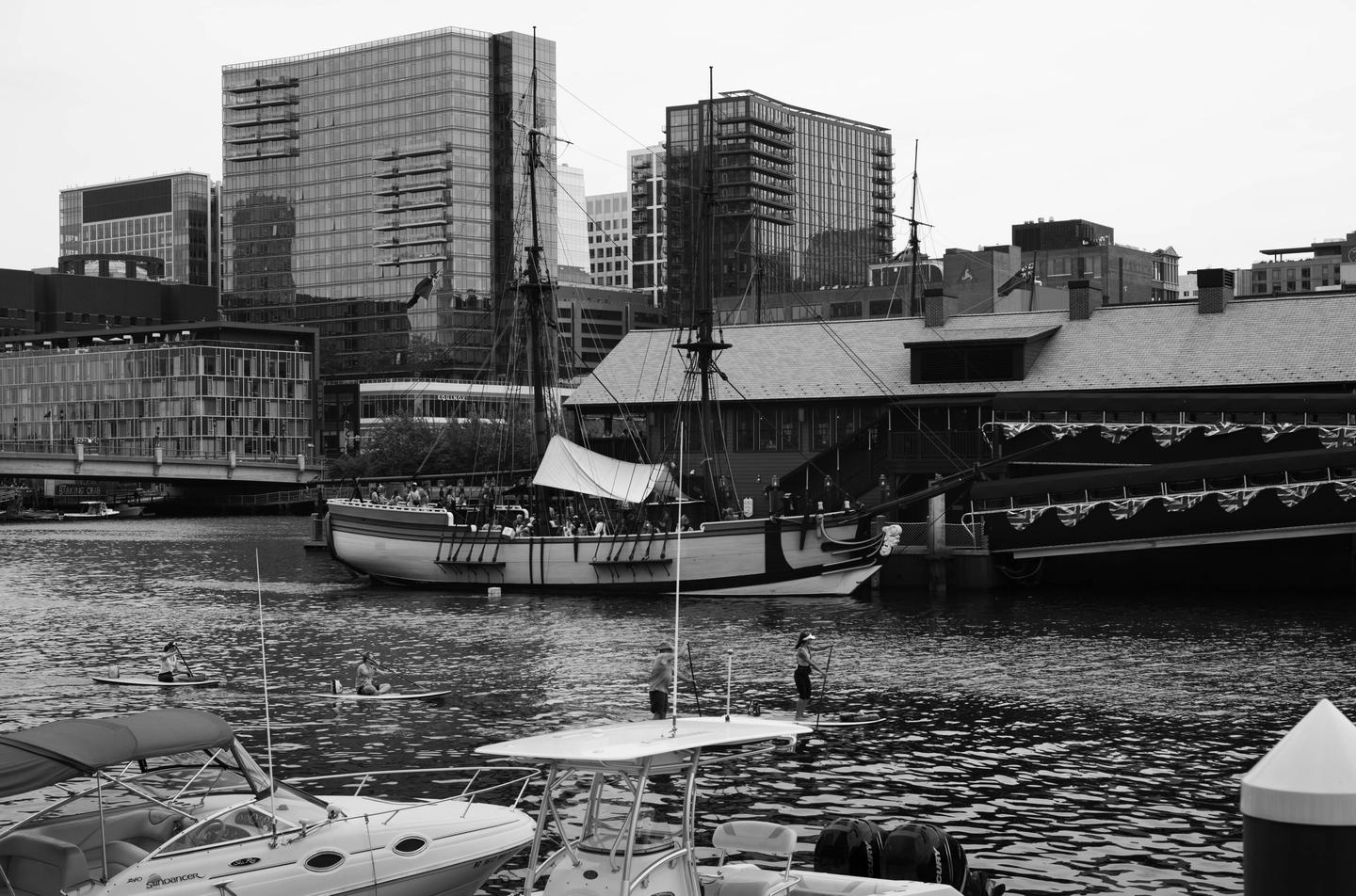
EXIF
- LEICA M10 MONOCHROM
- Summicron-M 1:2/50
- 50mm, 1/500s, f/5.6, ISO 160
- 📷 View Original
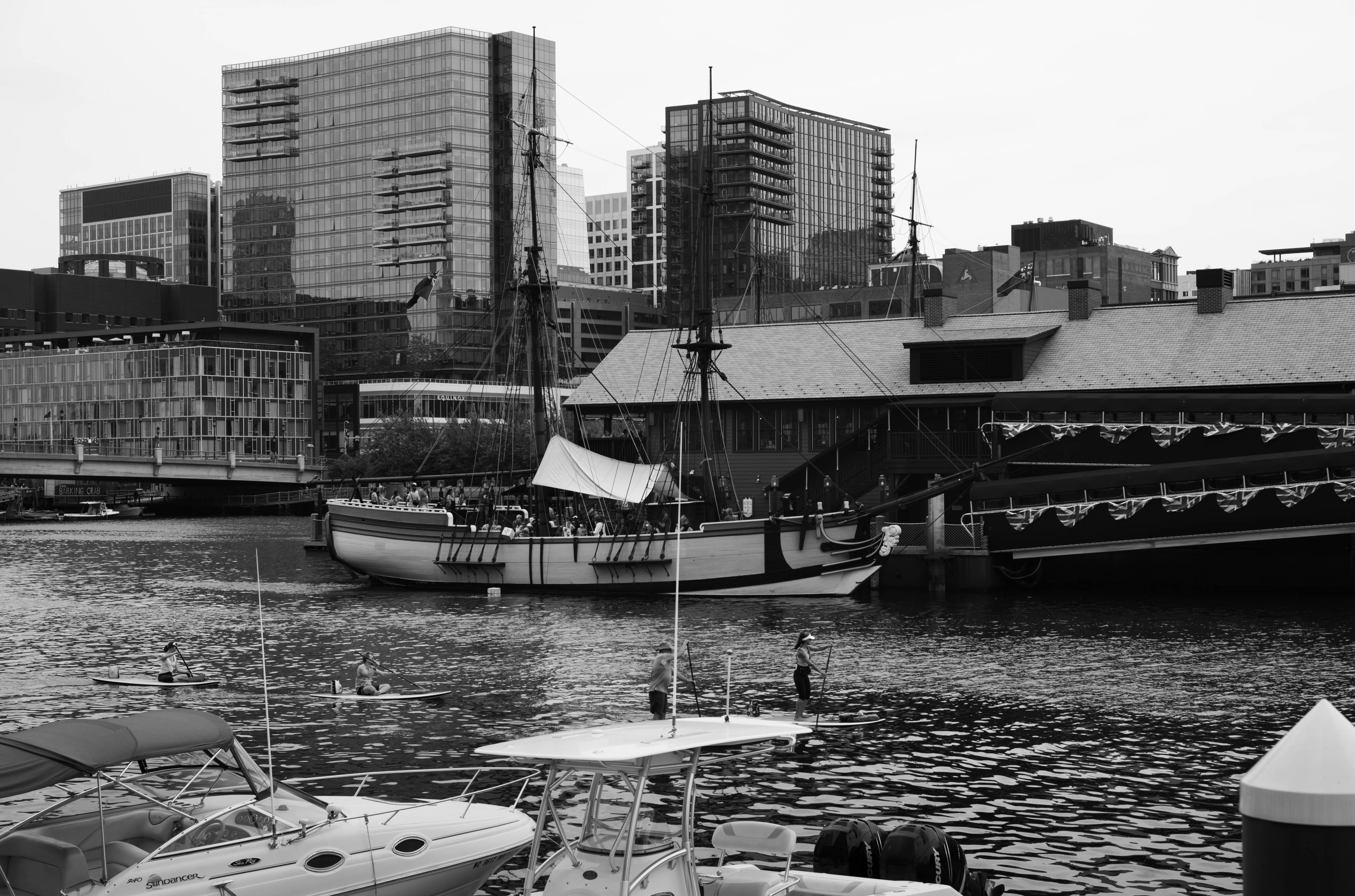{kind=link}
How to Find Broken Links With Python
I was fixing some broken links on our blog at work when I decided it would be fun to make my own broken link checker. It didn't end up being very complicated at all, and I'm glad that I no longer need to open a web browser and navigate to an ad-infested website to check if a page has broken links.
Here's the code below if you want to use it.
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
def get_broken_links(url):
# Set root domain.
root_domain = domain.com
# Internal function for validating HTTP status code.
def _validate_url(url):
r = requests.head(url)
if r.status_code == 404:
broken_links.append(url)
# Make request to URL.
data = requests.get(url).text
# Parse HTML from request.
soup = BeautifulSoup(data, features="html.parser")
# Create a list containing all links with the root domain.
links = [link.get("href") for link in soup.find_all("a") if f"//{root_domain}" in link.get("href")]
# Initialize list for broken links.
broken_links = []
# Loop through links checking for 404 responses, and append to list.
with ThreadPoolExecutor(max_workers=8) as executor:
executor.map(_validate_url, links)
return broken_linksPython Automation is Awesome!
I'm not a developer by trade, but I know just enough Python to automate repetitive tasks. Today at work, I saw an opportunity to speed up a task by writing a few lines of Python. Without going into too much detail, the task involved finding all the blog posts without a table of contents section.
We have a ton of content on our blog, so going through each post manually would've taken forever. To speed things up, I spent a few minutes writing the Python script below. To create the list of posts to check, I grabbed all the URLs from our sitemap, formatted them into a Python list, and assigned the list to the blog_urls variable. Finally, I ran the script. A few minutes later, I had a complete list of all the blog posts that don't have a table of contents section.
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
blog_urls = [(LIST OF URLS)]
def check_toc_status(url):
r = requests.get(url)
html = r.text
soup = BeautifulSoup(html, features="html.parser")
if soup.find_all("aside", {"class": "toc"}):
print(f"OK: {url}")
else:
print(f"NO: {url}")
if __name__ == '__main__':
with Pool(8) as pool:
result = pool.map(check_toc_status, blog_urls)A Quick Update
I haven't written anything for a few weeks, so I wanted to post a quick update.
- I've been super busy with life and work since the beginning of the year. We're moving to a new apartment in the coming weeks, so preparing for that has consumed a lot of my time. I'm happy to report that I'll finally have a dedicated home office at our new place, so I'm excited to be able to work anytime without worrying about being too loud.
- Work has been busy as well. We recently launched DevKinsta, an awesome (and free) tool for deploying local WordPress sites. Check it out if you're a WordPress developer, or if you have a curious mind.
- I've been spending almost all of my free time on Clubhouse. I didn't really get it at first, but now I do. I've met a lot of interesting people on there over the past few weeks. I have a lot to say about Clubhouse – too much for this update, so I'll share more of my thoughts in an upcoming podcast.
- I've been playing around with a site redesign. The previous codebase was hacked together over the past two years, and I felt like it was finally time to clean things up. I'm still working on the frontend code, but I was able to slim down my backend code significantly. This time around, I decided to try out Tailwind CSS as a design framework of sorts. I think I've finally wrapped my head around how it works, so I'm planning to finish up the redesign in the next few weeks.
Not sure if I'll have time to post again before moving. If not, I'll be back in late-February! In the meantime, you can probably catch me on Clubhouse.